区分値機能の概要
DBFluteのClassification機能(区分値機能)について、「DBFLUTE-495」の説明と合わせて、おさらいしたいと思います。
ここで言うClassificationとは区分値のことです。
例えば「会員ステータス」:
o FML : Formalized : 正式会員
o PVS : Provisional : 仮会員
o WDL : Withdrawal : 退会会員
こういった区分値をどう管理するかどう実装するか、かなり現場によってバラツキがあります。
まあ、バラついてたとしても困ったことがなければ良いですが、こんなプログラムが良くあったりましす。
// Set an entity property. entity.setMemberStatusCode("PUS"); // Determine an entity property. if (entity.getMemberStatusCode().equals("FNL")) { } // Set a condition to condition-bean. cb.query().setMemberStatusCode_Equal("WBS");
当然のことながら、間違いやすい訳で。
テーブル区分値でちゃんとFK制約があれば間違いはすぐにわかりますが、それよりも...
o DBAが区分値のリファクタをしたくてもできない
o ディベロッパーが「あの区分値なんだっけなぁ...」って探してる
っていう問題が地味にあります。
DBFluteのClassification機能を使うと以下のような感じになります;
// Set an entity property. entity.setMemberStatusCode_Provisional(); // Determine an entity property. if (entity.isMemberStatusCodeFormalized()) { } // Set a condition to condition-bean. cb.query().setMemberStatusCode_Equal_Withdrawal();
見ての通り、区分値を解決するメソッドが自動生成され、それを使うことで、タイプセーフに区分値を扱うことができます。
これなら、区分値をリファクタしたいときに、コードの変更が実装に影響を与えないですし、削除や名前変更があった場合は、影響範囲がコンパイルエラーで検知できます。
メソッドの補完で選択する形なので、ディベロッパーは、JavaDocに書かれた区分値のコメントを見ながら選択することができます。(区分値のコメントの設定については後述)
「あの区分値なんだっけなぁ...」っていうのはありません。
<Entity:会員を退会会員に設定>

[追記: 2010/04/07]
0.9.6.7より、entity.setMemberStatusCode_Withdrawal()形式をメインのやり方としています。
(但し、entity.classifyXxx()も利用可能です)
<Entity:会員が正式会員か否かを判定>
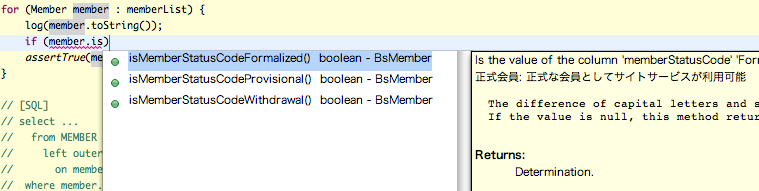
<ConditionBean:仮会員であること、という条件を設定>

ENUMやstatic finalに定義された区分値を利用するやり方をよく見掛けますが、やはりメソッドになって補完で選ぶだけの方が実装しやすく、ディベロッパーに使ってもらいやすいです。
(使ってもらう、ように仕向けるってのが実はとても大事)
区分値機能のメリット
また、このようにDBFluteで明示的に機能にすることによって、「DBFluteを使ってるプロジェクトでは区分値の扱い方が同じ」となり、別の会社の別のプロジェクトに行ったとしても、ディベロッパーは新しい環境での適応がとても速くなります。
そして実装面というだけでなく、区分値の管理方法という意味でも、DBFluteのClassification機能がきっかけでプロジェクト間でのバラツキがなくればいいなぁと考えています。
ぜひ、DBFluteを利用されている方はこのClassification機能をご利用下さい。ディベロッパーの方は、このClassification機能が設定されてないな、と思ったらアーキテクトの方に相談して下さい。
で、どのように設定するのかを説明します。
必要な情報は以下の二つです:
o 区分値の定義(どんなコードでどんな名前で)
o 区分値の配置(どのカラムにどの区分値が関連付くのか)
DBFluteプロパティ(dfprop)に当てはめるとこのような感じです。
区分値の定義:classificationDefinitionMap.dfprop
区分値の配置:classificationDeploymentMap.dfprop
区分値機能の設定方法
そして、これらを設定する大きく三つの方法があります。
A. ベタ
B. テーブル区分値
C. ERDコメント
それぞれの方法を以下のポイントと共に説明します:
o 区分値定義の一元管理
o ディベロッパーへの横展開
A. ベタ
現場ソリューション DBFlute(PDFファイル)で紹介されている
のはこのやり方です。
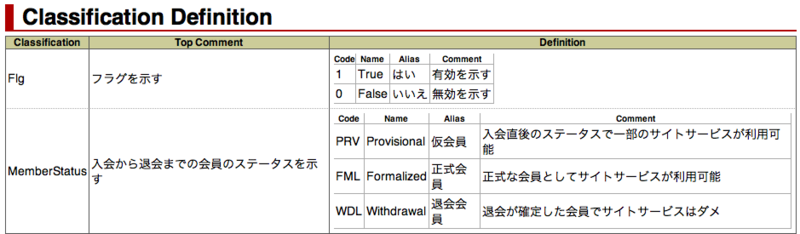
@classificationDefinitionMap.dfprop (UTF-8) map:{ ; MemberStatus = list:{ ; map:{topComment=入会から退会までの会員のステータスを示す} ; map:{code=PRV;name=Provisional;alias=仮会員 ; comment=入会直後のステータスで一部のサイトサービスが利用可能} ; map:{code=FML;name=Formalized;alias=正式会員 ; comment=正式な会員としてサイトサービスが利用可能} ; map:{code=WDL;name=Withdrawal;alias=退会会員 ; comment=退会が確定した会員でサイトサービスはダメ} } } # ; 区分値名称 = list:{ # ; map:{topComment=[この区分値に関するコメント]} # ; map:{[区分値要素1]} # ; map:{[区分値要素2]} # ; map:{ # ; code=[コード値(必須): DBに格納されるコード値そのもの] # ; name=[名称(必須): メソッド名などに利用される] # ; alias=[別名(任意): 別名。JavaDocに表示に表示される] # ; comment=[コメント(任意): コメント。JavaDocに表示される] # } # ; map:{[区分値要素4]} # ; map:{...} # }
一つの区分値に複数の区分値要素を定義します。
nameはENUMの名前にも利用されるので、クラス名で利用できない文字列を含めることはできません。(先頭が数字とか)listの中の一つ一つのmapが一つ一つの区分値要素に対応します。
codeやnameなどの意味と役割は「A」だけでなく他のやり方でも同様です。
@classificationDeploymentMap.dfprop (UTF-8) map:{ ; $$ALL$$ = map:{suffix:_FLG=Flg} ; MEMBER = map:{MEMBER_STATUS_CODE=MemberStatus} ; MEMBER_STATUS = map:{MEMBER_STATUS_CODE=MemberStatus} } # ; 全てのテーブル = map:{カラム名(ヒント) = 区分値名称 ; ...} # ; テーブル名1 = map:{カラム名(ヒント) = 区分値名称 ; ...} # ; テーブル名2 = map:{カラム名(ヒント) = 区分値名称 ; ...} # ; ... = map:{...}
どのテーブルのどのカラムにどの区分値を関連付けるかを定義します。$$ALL$$は「全てのテーブルの該当するカラムに関連」となります。カラム名は完全一致でなく、ヒントにすることが可能です:
o suffix:_FLG --> 後方一致
o prefix:FLG_ --> 前方一致
o contain:_FLG_ --> 中間一致
ヒントは主に$$ALL$$と合わせると良いでしょう。
例えば、MEMBER_STATUS_CODEを表現するカラムがどのテーブルでも「MEMBER_STATUS_CODE」と完全一致する、もしくは、で終わるとかであれば、$$ALL$$に関連付ければ設定は楽になります。
「A」は、非常にプリミティブなインターフェースです。
その他の方法を利用するにしても、この方法と併用することがありますし、また、区分値を定義するとはどういうことなのかを理解するのに非常にわかりやすい仕様なので、この方法は必ず覚えておくと良いでしょう。
「区分値定義の一元管理」がこの方法で一番課題になる部分です。
「プロジェクトで区分値定義をどこで管理するか?」
この方法は設定ファイルにベタっと定義を書きますので、区分値定義を他のところで管理する場合は、設定ファイルを自動生成でもしない限りは定義が冗長化します。
その場合は、ちょっとしたScriptを独自に作ってこの区分値定義を自動生成するようにするのがお奨めです。
もし、DBFluteプロパティの区分値定義で管理するの問題ないなら、それはそれで良いでしょう。区分値は必ずディベロッパーや仕様策定車の見やすい形で提供することが大切です。三つのポイントの一つ「ディベロッパーへの横展開」です。当然このDBFluteプロパティではそれを満たせませんが、Docタスクで生成されるSchemaHTMLで定義された区分値を一覧として参照することができます。
さらにその一覧へ、それぞれのカラムのからリンクで辿れます。ぜひdbflute-basic-exampleのSchemaHTMLをご覧下さい。
MEMBERのMEMBER_STATUS_CODEのMemberStatusへのリンクから区分値の一覧へ飛んで見て下さい。
Exampleなので、ちょっと区分値が少なくて物悲しいですが、実際の業務ではかなり壮観なドキュメントとなります。区分値の「ディベロッパーへの横展開」はこれでかなりいい感じです。
これは「A」以外の方法でも共通です。DBFluteのClassification機能を利用する限りはこの恩恵を得ることができます。
B. テーブル区分値
テーブル区分値とは、テーブルのデータとして管理されている区分値です。
ExampleDBで言うと、MEMBER_STATUSがまさにそうです。
FK制約でのチェックも入り、SQLでの結合で名称など取得することができるため、そのメリットは大きいです。jflute自身もDB設計をやるときはこのようにテーブル区分値を利用します。
(但し、全ての区分値を一つのテーブルにまとめるやり方は絶対にしない)
この場合、区分値はマスタデータとして管理されます。
例えば、ReplaceSchemaで利用するエクセルデータとして管理したり、その他別の方法でとにもかくにもDBに登録することになります。
なので、その状況で「A」の方法でそのままベタにDBFluteプロパティに定義をすると、定義が冗長することになります。データやエクセルから「A」のやり方の設定ファイルを自動生成すれば問題はないのですが、実はDBFlute自身がそれに近いやり方を既に提供しています。
GenerateタスクやDocタスク実行時に、区分値が登録されたテーブルに対して、実際にSQL文を発行して定義を取得する機能があります。
@classificationDefinitionMap.dfprop (UTF-8) map:{ ; MemberStatus = list:{ ; map:{topComment=会員の状態を示す} ; map:{table=MEMBER_STATUS ; code=MEMBER_STATUS_CODE ; name=MEMBER_STATUS_NAME ; orderBy=DISPLAY_ORDER } } } # ; 区分値名称 = list:{ # ; map:{topComment=[この区分値に関するコメント]} # ; map:{table=[テーブル名(必須): 該当区分値のテーブル名] # ; code=[コードカラム(必須): コードが格納されているカラム名] # ; name=[名称カラム(必須): 名称が格納されているカラム名] # ; alias=[別名カラム(任意): 別名が格納されているカラム名] # ; comment=[コメントカラム(任意): コメントが格納されているカラム名] # ; where=[絞り込み条件(任意): ex. FOO_FLG != 0] # ; orderBy=[ソートカラム(任意): ソート用のカラム名] # ; exceptCodeList=[除外コード(任意): ex. list:{FOO;BAR}] # ; suppressAutoDeploy=[自動デプロイOFFか否か(任意): @0.9.5.2] # } # }
区分値がどのテーブルのどのカラムに定義されているかを設定します。tableが指定されていることがテーブル区分値であることの目印となります。
このように設定するとGenerateタスクやDocタスク実行時に、これらの情報を元にSelect文を発行して区分値定義を取得します。
これにより、「区分値定義の一元管理」は解決です。
エクセルに区分値を追加したらReplaceSchemaを実行して、GenerateタスクやDocタスクを実行すれば、その追加された区分値はすぐに自動生成されたクラスやSchemaHTMLに反映されます。「ディベロッパーへの横展開」は「A」と同じくSchemaHTMLです。
テーブル区分値をExcelで管理しているくらいなら、それをReplaceSchemaで実行して(できるようにして)、この「B」の方法を利用すればDBFluteのClassification機能のメリットを簡単に享受できます。
区分値の配置(classificationDeploymentMap.dfprop)の設定は要りません。
DBFluteがどのカラムが区分値対象なのかを区分値の定義から判断して、かつ、リレーションを辿って自動登録します。
実は、これが「DBFLUTE-495」での修正で、DBFlute-0.9.5.1からの仕様となります。それまでは区分値定義はDBから取得するものの、それを「A」と同じようにカラムに関連付けてあげる必要がありました。
そういうこともあり、DBから取得する機能はずっと前のバージョンからあったにも関わらず露出が少なかった要因の一つです。なので、この機能を利用される場合は、DBFlute-0.9.5.1以降を利用する方が良いでしょう(C#版だとDBFlute.NET-0.8.9.1以降)。
但し、主に日本のシステムだと、コードと日本語名だけで管理するテーブルが多いかと思われます。実際にアプリケーションとしてはそれだけしか必要としないからです。すると、メソッド名などで利用する区分値の名前(name)をコードと日本語名のどちらかにするしかありません。上記のMEMBER_STATUSの例を見ると日本語名をnameに指定して、aliasは省略してnameと同じになるようにしています。すると、生成される区分値のメソッド名の一部は日本語になってしまいます。それで問題ないというのであれば、特に気にすることはありません。日本語名のメソッドはそれはそれでとてもわかりやすいです。
気になる方は、コードをnameにするか、別途英名が格納されるカラムを追加して、それをnameに指定した方がよいでしょう。
また、フラグのようなテーブル区分値にはなかなかならないものは、やはり「A」のやり方を使って定義します。そう言う意味で、「A」と「B」は併用するような形となります。
この方法を利用したExampleはdbflute-guice-exampleです。
C. ERDコメント
「ディベロッパーへの横展開」を徹底して追求した方法です。
ERDのコメントに書くのは非常に効果があります。
ExampleDBのERDをご覧下さい。
あまりドキュメントがたくさんあるのもよくありません。
ディベロッパーは他にもたくさんドキュメントを見る必要があり、あまり多いと見なくなってしまう可能性があります。
ERDの中に区分値が表現されていれば、あっちみたりこっちみたりをする必要がなくなります。(同じDB系の情報なのでなおさら)
ERDはプロジェクトメンバー間の情報伝達・意識確認の際の中心的なドキュメントです。ERDみながら会話をして仕様のやり取りをします。
そのとき区分値の定義が一緒であれば、会話が弾みます。その時会話をさえぎってわざわざ別のドキュメントを開いたり、印刷したりとかしないものです。区分値が別ドキュメントだと、「確かこうそういう区分値があったから、これこれこうだよな」って曖昧な確認で会話を終わらせてしまいがちです。
よくエクセル(だけ)で管理されているのを見掛けますが、あまり参照されないドキュメントになるのをよくみかけます。
もっと気軽に開けて参照しやすいドキュメントが良いです。
エクセルはセキュリティソフトとの関連で開くのが非常に遅かったり、開きっぱなしにしづらい(したくない)ものです。
開きやすいこと、開きっぱなしにしやすいこと、これが大事です。
ERDは大抵のツールでHTML出力できます。SchemaHTMLも同様ですが、ブラウザは大抵の人が起動しっぱなしで扱いやすく、今の時代のブラウザならWindowsのタスクバーを埋め尽くすこともないでしょう。
(エクセルだとすごいあっという間に埋まりますよね...)
と、ERDのコメントに書くことが有効であるということを語らせて頂きましたが、そのコメント上の定義をDBFluteの区分値定義に関連付けてあげなければなりません。
そこで、コメント欄に区分値を書くときに、とある規則で書くようにします。
[会員ステータス]: MEMBER_STATUS_CODE $ MemberStatus, 会員の状態を示す - FML, Formalized, 正式会員, 正式な会員を示す - PRV, Provisional, 仮会員, 仮の会員を示す - WDL, Withdrawal, 退会会員, 退会した会員を示す # [区分値タイトル(必須)]: 関連付けるカラム名(任意) # $ 区分値名称(必須), 区分値のコメント(任意) # - コード(必須), 名称(必須), 別名(任意), コメント(任意) # - ... # - ...
「区分値タイトル」は中身は任意で特にDBFluteでは利用しません。 "[Xxx]"の形式で書いてあれば何でもよく、わかりやすい業務的なタイトルをつけるのがドキュメント的に好ましいです。 「関連付けるカラム名」はclassificationDeploymentMap.dfpropの「$$ALL$$」に関連付けるカラムを指定する項目です。 "[Xxx]"の後の半角コロン「:」で区切ったその後の文字列が全てカラム名として扱われます。前方一致や後方一致を表現するときは「*」を利用します。 「*_FLG」で「_FLG」で終わるカラムに関連付けることになります。 無論、classificationDeploymentMap.dfpropを利用して個別定義も可能です。 別名とコメントは任意で、省略時はカンマも省略して構いません。必須のものだけで設定をすると以下のようになります:[会員ステータス] $ MemberStatus - FML, Formalized - PRV, Provisional - WDL, Withdrawalこのような形で記述して、ERDツールのエクスポートの機能で、「コメント文字列を含んだなにかしらのテキスト」を出力して下さい。 区分値定義の文字列が改行が保たれたまま含まれていれば、XMLでもHTMLでも形式はなんでも構いません。例えばEA(Enterprise Architect) であればXMLファイルをエクスポートすればOKです。 改行のは「& # x A ;」でも構いません。(記事上の都合によりわざと空白あけて記載しています) Encodingはデフォルトで「UTF-8」。XML定義のように一行目に「encoding="SHIFT_JIS"」というように定義されている場合はSHIFT_JISとなります。 (EAで出力したXMLであればこれが活用されます) それを、classificationResource.dfpropという名前でdfprop配下に配置します。DBFluteはこのファイルの中の文字列から決められた フォーマットの区分値定義を読み込んで自動登録します。 但し、テーブル区分値の場合は、そのテーブルのデータとERDのコメント欄の定義が冗長化してしまうところがトレードオフです。 「区分値定義の一元管理」に問題があります。こちらは現在改善を模索中です。テーブルとカラムの対応を定義するようにして(できるだけ簡単に)、ReplaceSchemaでそれを読み取って、自動で登録するような形にできないかと。 この方法を利用したExampleはdbflute-mysql-exampleです。まとめ
<A. ベタ> 区分値定義の一元管理:やり方次第 ディベロッパーへの横展開:Good! <B. テーブル区分値> 区分値定義の一元管理:Best! ディベロッパーへの横展開:Good! (But テーブル区分値でしか利用できない) <C. ERDコメント> 区分値定義の一元管理:テーブル区分値だとOUT! ディベロッパーへの横展開:Best! テーブル区分値なら「B」を利用して、フラグなどテーブルで管理されないちょっとした区分値に対してのみ「A」を利用する、が一番の基本になります。 「C」はDBAの気合いが要りますが、乗り越えればかなり強力でしょう。 (将来的には一元管理の問題にも対応したいと考えています)補足1
区分値を利用したいのは、DBFluteが自動生成したEntityやConditionBeanだけではありません。アプリケーションで作成したDTOなどで利用したい場合もあります。その場合は、allcommonパッケージ配下に生成される「CDef」というクラスを利用します。「CDef」は「ClassificationDefinition」の略です。 CDefはインターフェースで、そのインナークラスとして全ての区分値ENUMが定義されていて、「CDef.MemberStatus」というように利用できます。String code = CDef.MemberStatus.Formalized.code(); CDef.MemberStatus def = CDef.MemberStatus.codeOf(code);全ての区分値ENUMはCDefインターフェースをImplementsしています。code()やname()やalias()を透過的に扱うことも可能です。実はこれが「DBFLUTE-505」となります。 ちなみに余談ですが、これを作る上で以前迷ったのが、「一つ一つのENUMを一つのJavaファイルで作るか、CDefにまとめるか」です。 一つ一つのENUMを一つのJavaファイルになっている方が一般的かなと思っていながらも、実現する上で内部的な管理が煩雑になりやすいので、CDefにまとめる方法を採用しました。どのみちDBFlute方式だと、ディベロッパーはこのCDefはほとんど意識する必要ないというのも理由で。 しかし、いざCDefを直に使う機会があって使ってみると、非常に実装がしやすいことがわかりました。というのは「CDef」と書いて補完をすればENUMの一覧が補完されてJavaDocも見れてわかりやすいからです。 これがそれぞれ独立したENUMだとまずどんなENUMがあるのか知ってないとファーストタッチが進みません。またテーブル区分値の場合は、Entityのクラス名と区分値のENUM名が似てることが多く(というか全く同じとか)、すると、補完する上でとても面倒になりやすいです。 結果的に「CDef」で良かったと思っています(実現も管理も楽だし)。補足2
Classification機能を使っても、Entityのプロパティの型は変わりません。 なので、もともとのネイティブな型でのSetterなどは残っています。 これは以下の利用で残っています: 1. 内部利用で必要なため 2. 外部ツールがENUMに対応していないことが多いため 3. 主にWEBだとコード値そのままで扱うことも多いため 「2」の外部ツールは例えばBeanUtilsなどリフレクションでDTOと詰め替えるようなユーティリティです。YmirのConverterも同様です。ネイティブな型でのSetterが無いとそういったツールと非常に相性が悪くなってしまいます。また、アプリケーションで独自にそういった仕組みを実装するときも、その部分がトラブルを生みやすくなります。 「3」は、例えばリストボックスで選択された値をそのまま条件にして検索するというような場合、文字列として飛んで来たコード値をそのままConditionBeanに格納します。ネイティブな型でのSetterがなければ、あまりENUMとして扱うことに意味がないにも関わらず、Setする直前でCDef.MemberStatus.codeOf(code)とやる必要があります。 セキュリティの面に関して、ネイティブな型でのSetterを無くしても、結局codeOfを使えば不正な値は簡単に入れられてしまうので、それよりはバランスのとれた区分値支援に徹するようにしました。 正直、ENUMがもっと高機能で、コードと名前を両方管理できるような仕組みがデフォルトで設けられていたらなぁと思います。 codeOf()メソッドも独自なので、外部ツールに呼んでもらうことを期待できるものではありません。ENUMにデフォルトで付いているvalueOf()メソッドはこういった区分値ENUMではなんの役にも立ちません。C#だとコードも管理できますが数値だけなんですよね...